Framework Overview
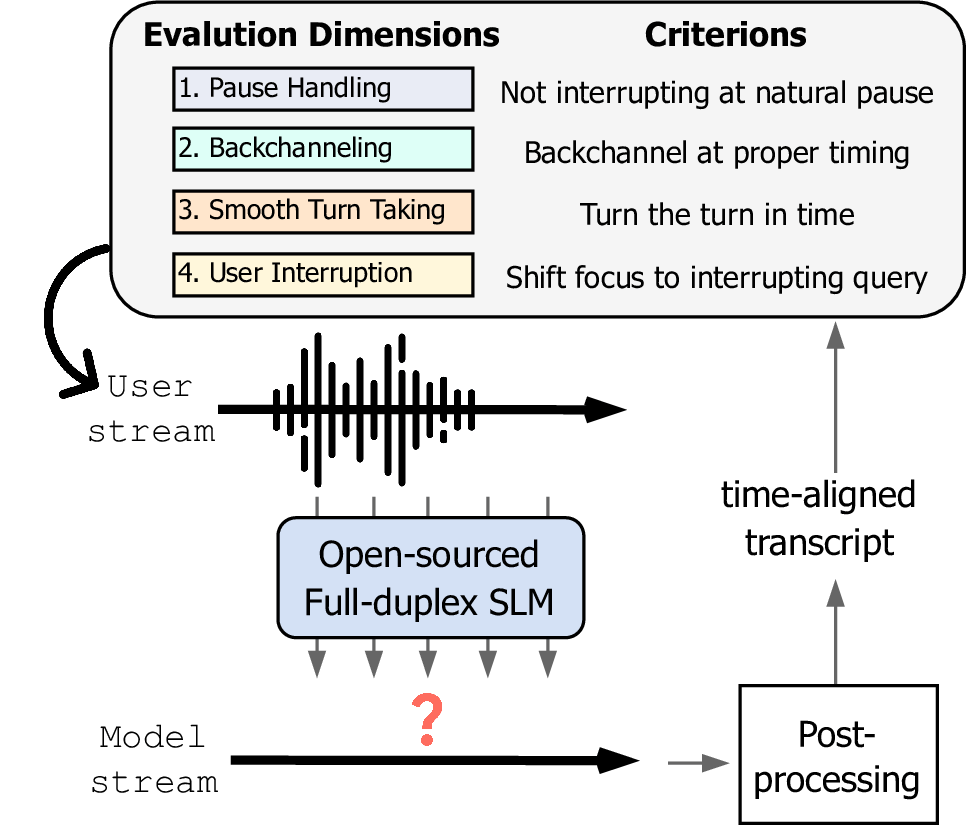
Figure 1: The Full-Duplex-Bench evaluation framework architecture.
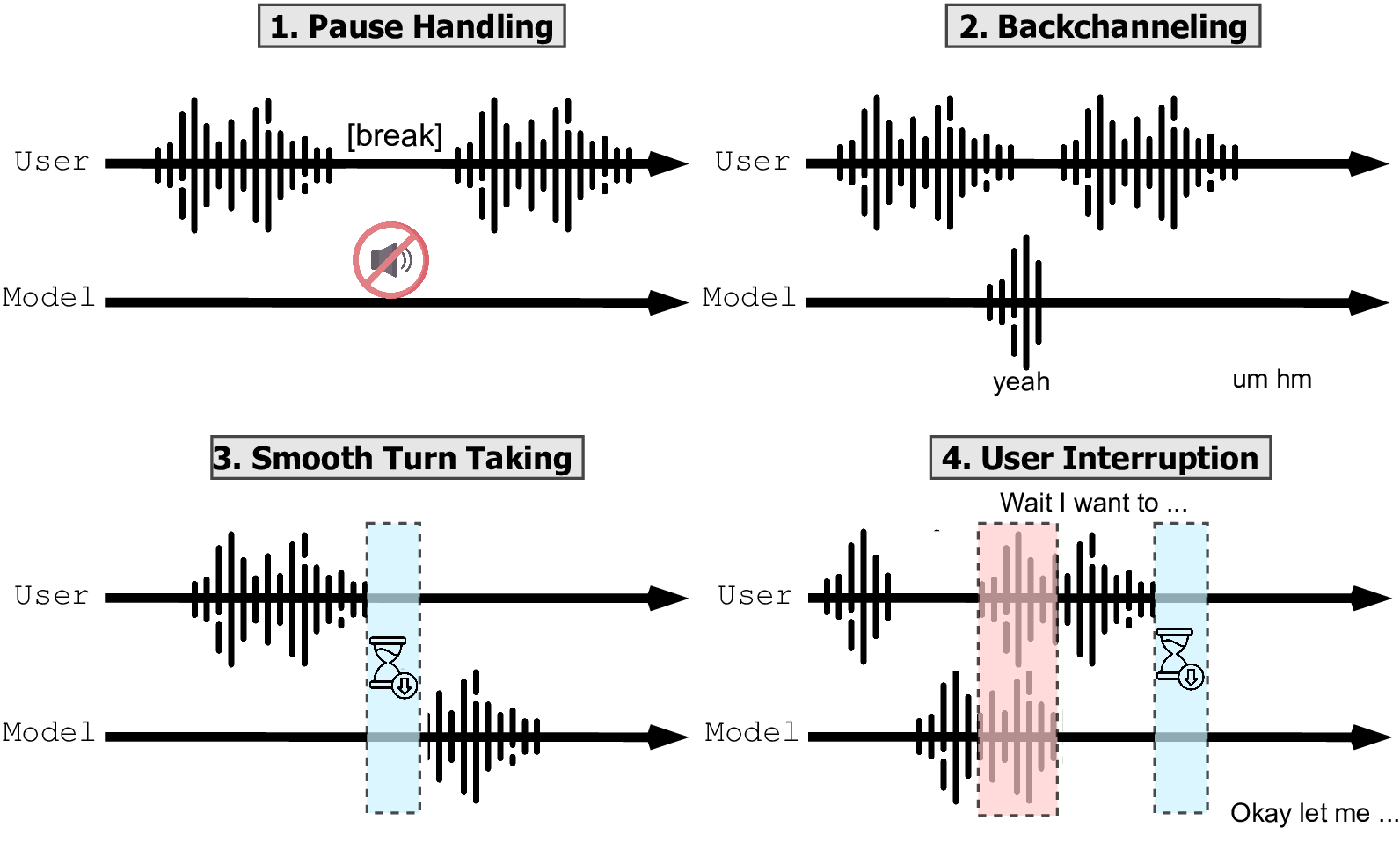
Figure 2: The four key dimensions evaluated in our benchmark.
Spoken dialogue modeling introduces unique challenges beyond text-based language modeling, demanding robust turn-taking, backchanneling, and real-time interaction. Although most Spoken Dialogue Models (SDMs) rely on half-duplex processing (handling speech one turn at a time), emerging full-duplex SDMs can listen and speak simultaneously, enabling more natural and engaging conversations. However, current evaluations of such models remain limited, often focusing on turn-based metrics or high-level corpus analyses (e.g., turn gaps, pauses). To address this gap, we present Full-Duplex-Bench, a new benchmark that systematically evaluates key conversational behaviors: pause handling, backchanneling, turn-taking, and interruption management. Our framework uses automatic metrics for consistent and reproducible assessments of SDMs' interactive performance. By offering an open and standardized evaluation benchmark, we aim to advance spoken dialogue modeling and encourage the development of more interactive and natural dialogue systems.
Full-Duplex-Bench evaluates spoken dialogue models across four key conversational dimensions:
Evaluates if models can recognize when a speaker pauses but still holds the turn. The ideal model avoids taking over during natural pauses. Measured by Takeover Rate (TOR) - lower is better.
Assesses if models provide appropriate listener responses (e.g., "uh-huh," "mm-hmm") without interrupting. Measured by Takeover Rate, Backchannel Frequency, and Jensen-Shannon Divergence (JSD) to compare model timing with human behavior.
Tests if models can detect turn boundaries and respond promptly. Measured by Response Latency - the time between the end of user speech and the start of model response. Lower latency indicates smoother turn-taking.
Examines how models handle and adapt to interruptions. Evaluated using Takeover Rate, GPT-4o Score (for response quality), and Latency After Interruption to measure response time following interruptions.
Performance comparison of dialogue models across our evaluation dimensions.
| Dimension | Pause Handling | Backchannel | Smooth Turn Taking | User Interruption | ||||||
|---|---|---|---|---|---|---|---|---|---|---|
| Synthetic TOR (↓) |
Candor TOR (↓) |
ICC TOR (↓) |
ICC Freq (↑) |
ICC JSD (↓) |
Candor TOR (↑) |
Candor Latency (↓) |
Synthetic TOR (↑) |
Synthetic GPT-4 (↑) |
Synthetic Latency (↓) |
|
| dGSLM | 0.949 | 0.953 | 0.782 | 0.013 | 0.950 | 0.989 | 0.572 | 0.895 | 0.201 | 3.972 |
| Moshi | 1.000 | 0.989 | 1.000 | 0.005 | 0.977 | 0.996 | 0.112 | 1.000 | 0.765 | 0.037 |
| Freeze-Omni | 0.672 | 0.287 | 0.782 | 0.002 | 0.984 | 0.369 | 1.168 | 0.795 | 3.371 | 1.200 |
Note: Bold numbers indicate best performance for each metric. Arrows indicate whether higher (↑) or lower (↓) values are better.
Below are sample interactions demonstrating different model behaviors across our evaluation dimensions.
| Sample ID | Model Responses | ||
| dGSLM | Moshi | Freeze-Omni | |
| 1 | |||
|---|---|---|---|
| 2 | |||
| 3 | |||
| 4 | |||
| 5 | |||
| Sample ID | Model Responses | ||
| dGSLM | Moshi | Freeze-Omni | |
| 1 | |||
|---|---|---|---|
| 2 | |||
| 3 | |||
| 4 | |||
| 5 | |||
| Sample ID | Model Responses | ||
| dGSLM | Moshi | Freeze-Omni | |
| 1 | |||
|---|---|---|---|
| 2 | |||
| 3 | |||
| 4 | |||
| 5 | |||
| Sample ID | Model Responses | ||
| dGSLM | Moshi | Freeze-Omni | |
| 1 | |||
|---|---|---|---|
| 2 | |||
| 3 | |||
| 4 | |||
| 5 | |||
| Sample ID | Model Responses | ||
| dGSLM | Moshi | Freeze-Omni | |
| 1 | |||
|---|---|---|---|
| 2 | |||
| 3 | |||
| 4 | |||
| 5 | |||